sql在应用中执行比较慢,在SSMS中执行比较快的问题处理
项目背景:
使用的数据库是sql server 2014 企业版。主表记录总共1.7万,在查询时随着翻页查询速度越来越慢。最后一页需要2s多才能查询完毕。
补充:第一页很快,最后一页最慢
具体情况:
涉及到的主要表 us_er数据量大概有1.7w
u_ser_order 有380条记录
u_ser_flow_loc 有 7.8w 条记录
select TTT.*,T.created lastTrackCreated , T.remark LastTracklog from
( select u_ser.*, crd.amount gmv from u_ser
left join u_ser_order crd on crd.u_serid=u_ser.id
where u_ser.tenantId=123456789
order by id desc OFFSET @row ROWS FETCH NEXT @size ROWS ONLY ) TTT
outer apply (
select top 1 clog.created,clog.remark from u_ser_flow_loc clog where clog.recordType=1 and clog.u_serId=TTT.id order by id desc) as T tenantId 是非聚集索引长整型,u_ser_order 中字段u_serId 是 u_ser的主键,但是未设置索引。
可以看到sql并不复杂,数据量微乎其微,不应该慢才对。
排查
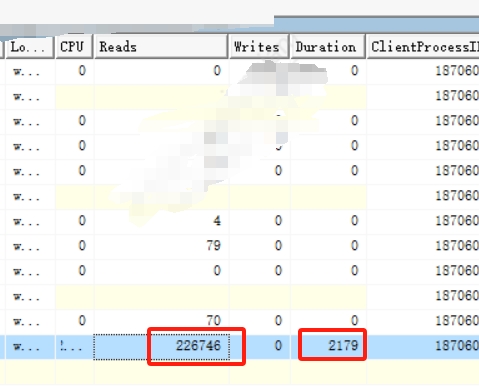
使用Profiler 跟踪查询语句,发小 Reads 数量是 226746,家人们,我实在不懂啊,为啥这么多呢
然后我将这个sql复制到的服务器上的 Management Studio中执行,结果是很快的32ms就完事儿了。
然后我开始分析查询计划,主要开销是u_ser 表的索引扫描开销是97% ,看不出有什么问题,反正实际执行计划页使用38ms就有结果了。
同时我在Profiler中监测到 Management Studio这个语句是很快的,这在我的知识盲区了。
抓耳挠腮半天。。。
没整明白到底怎么回事。然后将u_ser_order 中外键(u_serId)加上索引。业务中的查询快了起来,响应很快。
不过没整明白,这么少的数据至于慢么。于是又删除 u_ser_order 中 u_serId 的索引,奇怪的是前端业务查询依然很快,没有慢下来。臣妾不懂了!并优化了sql查询
select TTT.*,T.created lastTrackCreated , T.remark LastTracklog from (
select t1.*, crd.amount gmv from
(select * from u_ser order by id desc OFFSET @row ROWS FETCH NEXT @size ROWS ONLY ) t1
left join u_ser_order crd on crd.u_serid=t1.id
) TTT
outer apply (
select top 1 clog.created,clog.remark from u_ser_flow_loc clog where clog.recordType=1 and clog.u_serId=TTT.id
order by id desc
) as T 家人们谁能告诉呀,什么原因,怎样继续深入的查一下为什么原来要读22w个数据页。
2024-02-26 后续
查询速度自上次莫名其妙的好了以后不知道什么时候又开始慢起来了,经过排查和查阅相关资料,并在库中验证了,此问题与 数据库的 ARITHABORT 配置有关系,数据库服务默认其为ON,但是我的库不知道什么时候将其设置为OFF,故此出现此问题。
查询库的ARITHABORT配置
sql
SELECT name, is_ansi_nulls_on, is_ansi_padding_on, is_ansi_warnings_on, is_arithabort_on
FROM sys.databases
WHERE name = 'YourDatabase';将其设置为ON
ALTER DATABASE YourDatabase SET ARITHABORT ON;截至本次调整,我认为这个问题是sql在应用中执行比较慢,在SSMS中执行比较快的问题,然而并不是。请看下文分析
2024-03-05 续
继上次修改之后隔了几天这个查询再次慢下来,再次从Profiler中将执行的sql语句获取粘贴到ssms中执行。这次重现了这个语句的问题。因为前面几次拿到了sql语句在SSMS中我总是会调整格式后执行sql没有问题,这次没有调整格式,整个语句按复制出来的一整行执行却很慢。
sql语句如下(表名的~~并非错误,而是不能直接暴漏出来)
exec sp_executesql N' select TTT.*,T.created lastTrackCreated , T.remark LastTracklog from ( select clu~~e.*, crd.amount GMV from clu~~e left join clue_o~~er crd on crd.clueid=clu~~e.id where clu~~e.tenantId=4187194572532617216 order by id desc OFFSET @row ROWS FETCH NEXT @size ROWS ONLY ) TTT outer apply (select top 1 clog.created,clog.remark from clue_flow_lo~~c clog where clog.recordType=1 and clog.clueId=TTT.id order by id desc) as T', N'@tenantId bigint,……', @tenantId=xxxxxxx执行计划如下图
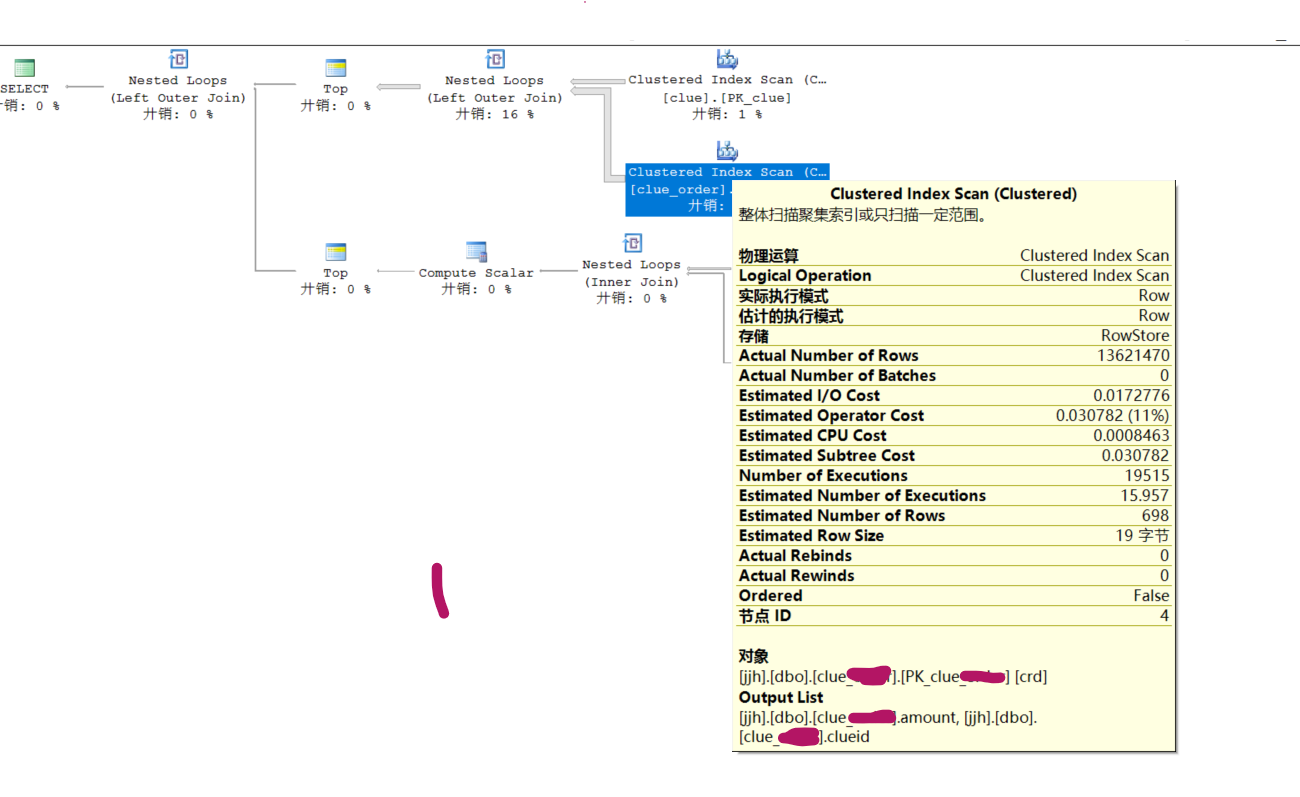
看到这个表实际只有不到700条记录,实际执行计划却执行了1300w+,就是这一步导致查询缓慢的,具体原因不得而知,但是通过sql语句分析不存在能让其执行1300w+的情况。
另:这个表的外键clueid未加索引
后面测试sql语句,在sql语句主体中:
- 增加空格
- 减少空格
- 修改表名(as语法的重命名)
- 在一个空白增加一个空格在另一个空白减少一个空格
- 换行
都会让查询快起来
- 禁用查询缓存(with recompile)
不会让查询快起来
逐考虑”表统计信息“,使用下面语句更新统计信息
UPDATE STATISTICS table_name;经过重试,查询速度恢复预期。查询计划有了一些变化
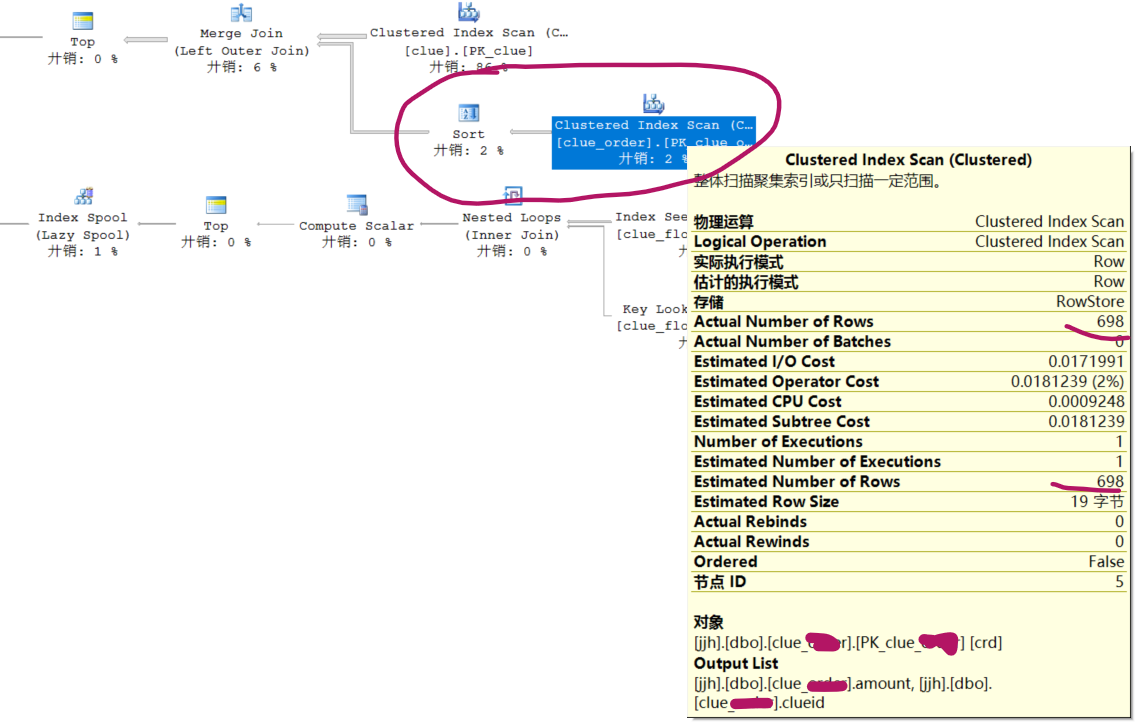
上午初步解决了这个问题。下午6点又开始慢起来,更新表统计表信息似乎并没有根本解决问题。本质上我是不愿意给clueid加索引,因为我认为不加索引这个数据量下也不应该这么慢。
参考资料:
1、SQL Server stored procedure runs fast in SSMS and slow in application
2、Slow in the Application, Fast in SSMS
3、排查数据库应用程序和 SSMS 之间的查询性能差异问题

本文链接:https://blog.nnwk.net/article/183
有问题请留言。版权所有,转载请在显眼位置处保留文章出处,并留下原文连接
Leave your question and I'll get back to you as soon as I see it. All rights reserved. Please keep the source and links
全部评论